MultiDialog Dataset
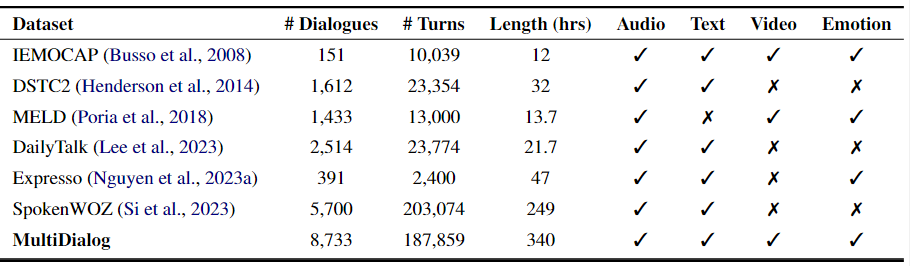
Table 1: Comparison of MultiDialog dataset with publicly available multimodal dialogue datasets.
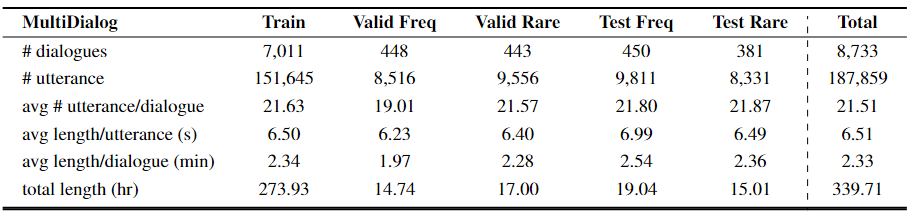
Table 2: Detailed statistics of MultiDialog dataset.
- Preparation. We gathered 12 fluent English speakers, with varying gender, age, and nationality. The participants, aged 20 to 25, came from six different countries, with six female and six male actors. We derived dialogue scripts from the open-domain dialogue dataset, TopicalChat which is a rich knowledge-grounded dataset collected from real human-human conversations.
- Recording. Data was recorded in a professional recording studio with a green screen and minimal background noise. During a recording session, two conversation partners sat side-by-side and were recorded with a separate camera and a microphone. The participants were asked to act according to a given script conveying the desired emotion annotation for each utterance. We specifically provided emotion instructions for visual cues based on the Facial Action Coding System and for audio cues based on prosody.
- Post-Processing. We had an annotator go through the audio-visual recordings to manually adjust the misalignments by sliding the start time. We segmented the recordings into conversations and turns based on the recorded timesteps of each turn. The MultiDialog dataset consists of approximately 340 hours of audio-visual videos of 9,000 dialogues between 6 pairs of conversation partners. The final statistics of our dataset are shown in Table 2.
Audio-Visual Spoken Dialogue System
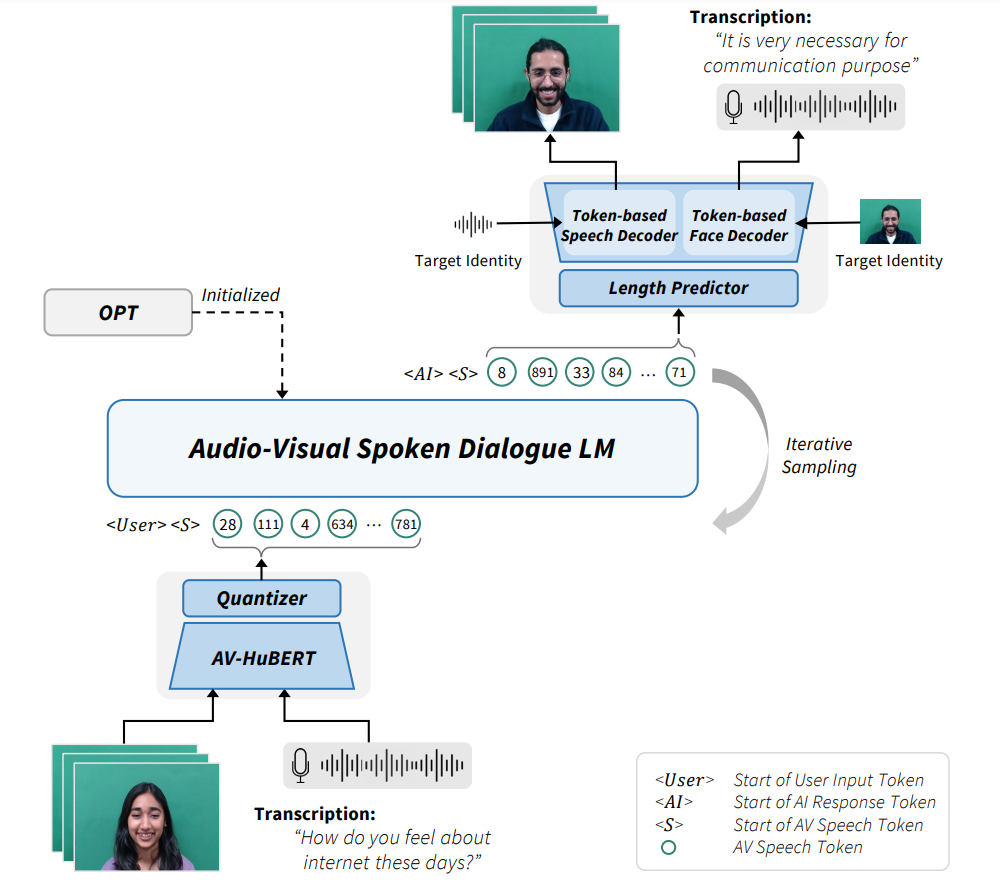
Figure 1: Overview of the proposed framework for multimodal spoken dialogue language modeling. With the AV speech tokens as the pseudo-texts, it can process audio-visual face video from the user input and generate corresponding responses as audio-visual face video.
- Audio-Visual Speech Encoding. We adopt a unified approach to model both audio and visual inputs into audio-visual speech tokens. Employing AV-HuBERT, a multimodal speech model, we extract audio-visual speech features to capture linguistic and phonetic information. These AV speech tokens are then used to train our Audio-Visual Spoken Dialogue LM.
-
Audio-Visual Spoken Dialogue Language Modeling.
We use a pretrained LLM, OPT-1.3B to initialize our model and combine the vocabulary of AV speech tokens with the original text vocabulary. This allows us to jointly model the probability of both AV speech tokens and text tokens. We introduce a joint speech-text pre-training scheme to effectively transform the text-based LLM into the AV speech token-based LLM, enabling it to produce relevant AV speech responses from the AI side given a conversation context. It proceeds in the following two stages:
The first stage is instructing the LLM to interpret and generate AV speech tokens. We segment the dialogue into turns and prepare paired AV speech tokens and text tokens. We then concatenate the pair to construct both audio-visual speech recognition (AVSR) and text-to-speech generation (TTS) training objectives. Only the embedding layer and the projection layer are trained, which guides the LLM to understand and generate AV speech tokens while retaining the given LLM knowledge needed for dialogue generation.
The second stage is jointly learning the text and AV speech token-based dialogue. We select either one of the speakers as the AI which the model aims to predict and indicate the start of the response with additional speaker prefix tokens. During the pretraining, we evenly mix the use of AV speech tokens and text which allows the model to utilize both token knowledge to generate dialogue response. We pretrain the entire model at this stage and we later finetune on pure AV speech token-based dialogue.
-
Audio-Visual Generation
The AV speech tokens are used to generate a response in the form of a talking face video. The audio-visual generator includes a length predictor, a token-based speech decoder, and a token-based face decoder. The token-based speech decoder and face decoder, adapted from the existing speech generator and face generator, process AV speech tokens instead of raw audio. Speaker identity information is incorporated through speaker embedding extraction, and the target identity's face and pose prior are utilized to enable generation with the desired identity.